TinyBrainGPT Language Model studio
A downloadable LLM creation studio
!!as of date there is a bug preventing the application from detecting GPU's I will be uploading a working fix within a few hours!!
# TinyBrain GPT — The World's First User-Friendly Windows Desktop LLM Training Studio For Consumers By Consumers
!!REQUIRES dotnet8 AND torchsharp to be installed!!!
# instuctions
1. download TinyBrainGPT Studio P1, P2, P3
2. extract each .zip
3. open P2 and P3 then open the second file, then copy the contents of both P2 and P3 into P1
4. install dotnet 8.0
5. download your cuda kit version 12.1
6. run the .exe file and configure then train
7. make sure you have official nvidia drivers installed
This is a quick beta release to make sure it works for testing.
currently it contains:
dataset and model config presets✅
100% from scratch no software limits LLM creation with FULL customization ✅
144+ pre selected and tested datasets to choose from to train you model ✅
Configurable % of the training is used for which dataset you select ✅
Custom made conversation / thinking datasets baked into the training ✅
Active training info and logs✅
Configurable Intelligence Checking throughout the training that automatically tests the bot using a pre set message so you can compare the smarts throughout training ✅
Pause the model and chat in the middle of training ✅
Persona/instruction box you can add whatever to ✅
GGUF exporting currently tested and working with Jan.ai ✅
---
Other model format exporting (will be added soon)❌
Online api search togglable for the model to have online acces (will be added soon)❌
LoRA (will be added soon)❌
Multigpu support (will be added in next update with configurations for what gpu does what) ❌
And here is a generated and very detailed description of every feature since I can't seem to find time to write it:
### BETA RELEASE
**Train, chat with, and export your own language models - entirely on your PC. No cloud. No subscriptions. No command line. No Python.**
Built from scratch in C#/.NET 8 with TorchSharp CUDA GPU acceleration. Train models from 60M to 1B+ parameters, chat with them mid-training, teach them to think step-by-step, and export to GGUF for use in Jan.ai, Ollama, or LM Studio.
---
## CORE PLATFORM
- Train real GPT transformer language models from scratch on your own GPU
- Beautiful dark-themed Windows UI - no terminal, no Python, no dependencies
- Models from 60 million to 1 billion+ parameters
- Chat with your model mid-training - pause, talk, resume from the exact step
- Everything runs 100% locally - your data never leaves your machine
- Three launch modes: Full GUI (default), Config-only (--config), Console (--console)
---
## MODEL ARCHITECTURE
Full GPT-style causal transformer with Pre-LayerNorm layout (same architecture as GPT-2):
- Token Embedding + Learned Positional Embedding with dropout
- N x TransformerBlock: LayerNorm, Multi-Head Causal Self-Attention, Residual, LayerNorm, FFN (GELU), Residual
- Final LayerNorm into Linear projection to vocabulary logits
- Combined Q/K/V projection (one matmul instead of three for efficiency)
- Scaled dot-product attention with causal mask (autoregressive)
- GELU activation with 3.7x expansion ratio in FFN
- Xavier uniform weight init with GPT-2 residual scaling
- Dropout at 4 points: embeddings, attention weights, attention output, FFN
---
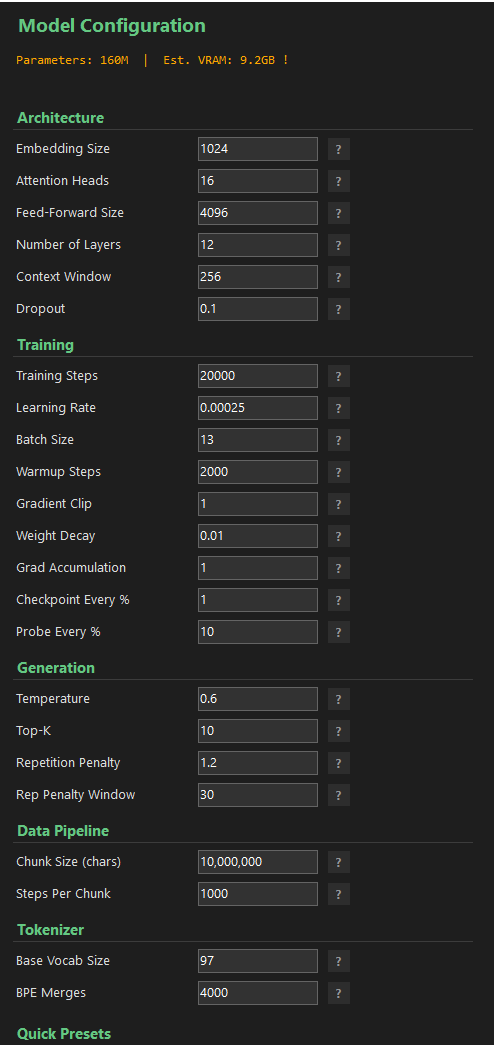
## 22 CONFIGURABLE HYPERPARAMETERS
Every parameter adjustable in the UI with a help tooltip explaining it in plain English. Live validation with color feedback.
### Architecture (6 parameters)
- Embedding Size (default 1024) - Token representation dimensionality. Bigger = smarter but more VRAM
- Attention Heads (default 16) - Parallel attention perspectives per layer
- Feed-Forward Size (default 4096) - Width of the FFN layer. Usually 3.5-4x Embedding Size
- Number of Layers (default 12) - Transformer blocks stacked. More = deeper understanding
- Context Window (default 256) - Tokens the model sees at once. Bigger = better coherence
- Dropout (default 0.1) - Regularization rate. 0.0 = off, 0.05 = mild, 0.1 = standard
### Training (9 parameters)
- Training Steps (default 20,000) - Total optimization iterations
- Learning Rate (default 0.00025) - Peak LR with cosine annealing. Too high = unstable, too low = slow
- Batch Size (default 13) - Examples per step. Reduce first if OOM
- Warmup Steps (default 2,000) - Linear LR ramp from 0 to peak. Usually 5-10% of total steps
- Gradient Clip (default 1.0) - Max gradient norm. Prevents training explosions
- Weight Decay (default 0.01) - AdamW L2 regularization to prevent memorization
- Grad Accumulation (default 1) - Micro-batches before update. Simulates large batches on small GPUs
- Checkpoint Every % (default 1%) - Auto-save frequency (1% = 100 checkpoints)
- Probe Every % (default 10%) - Intelligence test frequency. Watch your model get smarter
### Generation (4 parameters)
- Temperature (default 0.6) - Sampling randomness. 0.3 = precise, 0.6 = balanced, 1.0 = creative
- Top-K (default 10) - Only sample from K most likely tokens. 10 = focused, 40 = diverse
- Repetition Penalty (default 1.2) - Penalizes recent tokens. 1.0 = off, 1.2 = mild, 1.5 = strong
- Rep Penalty Window (default 30) - How many recent tokens to check for repetition
### Data Pipeline (2 parameters)
- Chunk Size (default 10,000,000 chars) - Training text loaded per rotation
- Steps Per Chunk (default 1,000) - Steps before rotating to fresh data from disk
### Tokenizer (2 parameters)
- Base Vocab Size (default 97) - Base character set. 97 = ASCII, 256 = byte-level, 360 = extended
- BPE Merges (default 4,000) - Learned subword pieces. 2K-40K depending on model size
---
## 7 ONE-CLICK MODEL PRESETS
Each preset auto-configures all 22 parameters. One click and you're ready to train.
- 60M (Fast) - 51M params, 768 embed, 6 layers, 30K steps, ~3 GB VRAM
- 150M - 144M params, 960 embed, 12 layers, 60K steps, ~6 GB VRAM
- 250M - 239M params, 1088 embed, 16 layers, 80K steps, ~7 GB VRAM
- 350M - 349M params, 1216 embed, 19 layers, 100K steps, ~8 GB VRAM
- 500M - 400M params, 1344 embed, 18 layers, 125K steps, ~10 GB VRAM
- 750M - 780M params, 1536 embed, 24 layers, 200K steps, ~20 GB VRAM
- 1B - 1.07B params, 1792 embed, 24 layers, 300K steps, ~34 GB VRAM
60M-500M designed for consumer GPUs (8-10 GB VRAM). 750M and 1B target high-end setups (24-48 GB).
---
## REAL-TIME VRAM ESTIMATION
Live VRAM calculation as you adjust parameters - accounts for model weights, optimizer state, gradients, activations, and CUDA overhead. Color-coded: green (safe), orange (tight), red (likely OOM).
---
## BPE TOKENIZER
- Byte-Pair Encoding trained directly on your data (5M character sample)
- Configurable: 97/256/360 base vocab + 2,000 to 40,000 learned merges
- Common subwords like "th", "ing", "the", "tion" become single tokens
- Binary save/load, auto-retrains if config changes
---
## TRAINING ENGINE
- AdamW optimizer with configurable weight decay
- Gradient accumulation: simulate large batches on small GPUs (e.g., batch 2 x accum 8 = effective 16)
- Gradient clipping: prevents training explosions
- Cosine annealing LR schedule with linear warmup (same as GPT-3/LLaMA)
- Checkpoint system: auto-saves at configurable intervals, config fingerprint for safety, auto-resumes on restart, corrupt checkpoints silently skipped
- Live metrics: percentage, ETA, smoothed loss, steps/sec, tokens/sec, color-coded status bar
- Training log: CSV file recording loss, probes, and events at every checkpoint
---
## INTELLIGENCE PROBES
Collapsible side panel that periodically tests your model during training:
- Asks "what are you" at configurable intervals (default: every 10%)
- Watch your model progress from gibberish to coherent answers
- Shows confidence score for each probe
- Results logged to CSV for analysis
- Panel auto-opens on first probe, toggleable with arrow button
---
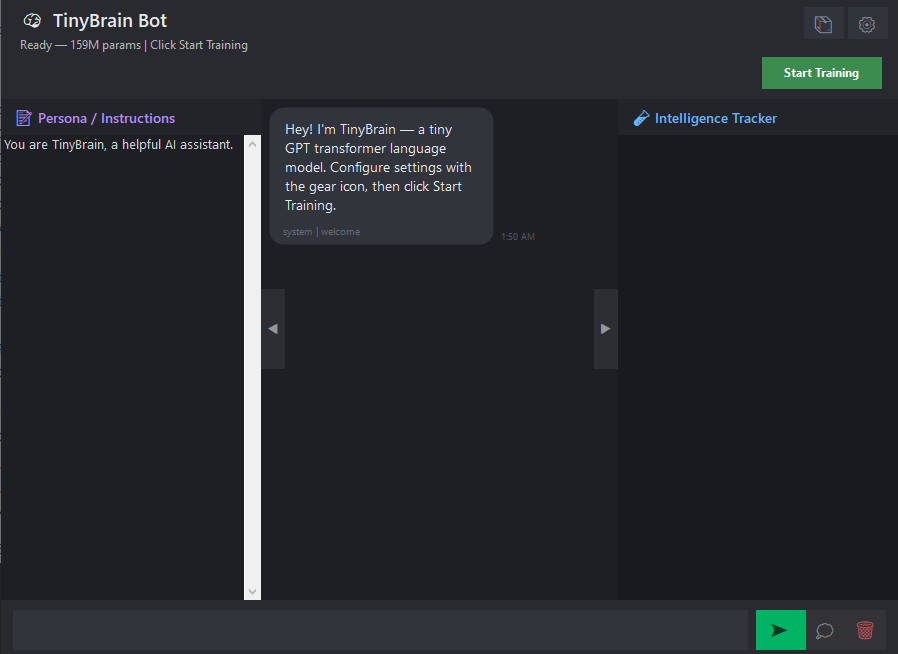
## PAUSE AND CHAT MID-TRAINING
The only LLM training app that lets you talk to your model while it's still training:
- Pause at any point, model switches to eval mode
- Chat with full interface: persona, thinking mode, conversation history
- Resume training from the exact same step - no data loss, model stays in GPU memory
---
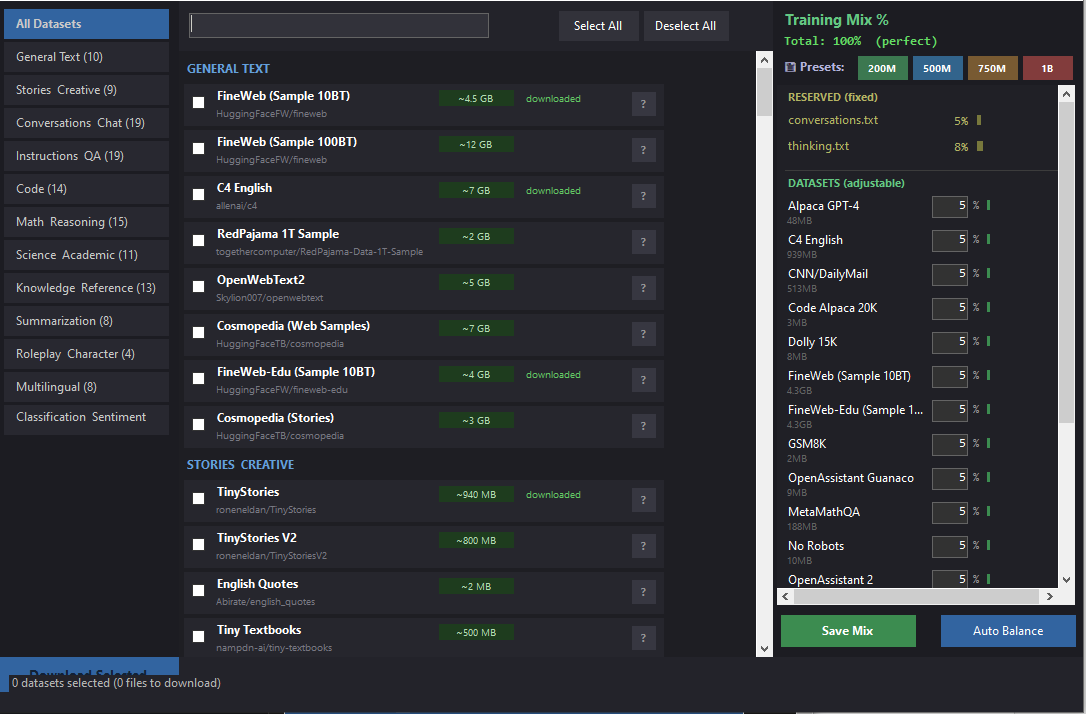
## 144 CURATED DATASETS ACROSS 12 CATEGORIES
Built-in dataset browser with search, download, and training mix configuration. All verified compatible with HuggingFace parquet API.
General Text (10): FineWeb, FineWeb-Edu, C4, OpenWebText2, RedPajama, Cosmopedia, Cosmopedia V2, Falcon RefinedWeb, Wikisource, SlimPajama
Instructions and QA (19): Alpaca Cleaned, Alpaca GPT-4, Dolly 15K, Open Platypus, Evol Instruct 70K, No Robots, GPTeacher, HC3, SQuAD v2, Natural Questions, FLAN V2, FLAN Collection, P3, HelpSteer, HelpSteer2, WizardLM Evol V2, Unnatural Instructions, Self-Instruct, Lima
Conversations and Chat (19): Anthropic HH-RLHF, OpenAssistant OASST2, ShareGPT Vicuna, OpenHermes 2.5, OpenOrca, Capybara, UltraChat 200K, UltraChat Full, UltraFeedback, SODA, DPO Pairs, Nectar, Deita 10K, Orca Chat, WildChat, Chatbot Arena, Lmsys Chat 1M, Magpie
Code (14): Code Alpaca 20K, StarCoder2, Dolphin Coder, Code Contests, CodeFeedback, CommitPack, Python 143K, Python Code Instructions, Python ShareGPT, Glaive Code Assistant, OSS Instruct, Magicoder Evol, Code Search Net, The Stack (Smol)
Math and Reasoning (15): GSM8K, ARC Easy, ARC Challenge, MetaMathQA, CoT Collection (1.84M examples), Orca-Math 200K, MathInstruct, OpenMathInstruct, OpenMathInstruct-2, AQuA-RAT, Camel Math, Open Web Math, Proof Pile 2, Cosmopedia Math, Balanced COPA
Knowledge and Reference (13): Wikipedia English, Simple Wikipedia, Stack Exchange Preferences, Stack Exchange Paired, Stanford Human Preferences, PIQA, BoolQ, WinoGrande, WebGPT Comparisons, MMLU, CommonsenseQA, OpenbookQA, Economics Dataset
Science and Academic (11): MedQuAD, Medical Meadow Flashcards, Medical Meadow WikiDoc, HellaSwag, ScienceQA, SciQ, Camel Physics, Camel Chemistry, Camel Biology, Cosmopedia Khan Academy, Medical QA
Stories and Creative (9): TinyStories V1, TinyStories V2, Tiny Textbooks, SODA Dialogues, SODA Synthetic, Quotes 500K, Poetry Foundation, Cosmopedia WikiHow, Cosmopedia OpenStax
Summarization (8): CNN/DailyMail, XSum, SAMSum, DialogSum, BillSum, Reddit TLDR, OpenAI Summary Feedback, Cosmopedia Stanford
Classification and Sentiment (14): AG News, Amazon Reviews, IMDB, Yelp Review Full, Tweet Eval, Twitter Financial Sentiment, Emotion, GLUE CoLA, GLUE MNLI, GLUE QNLI, GLUE QQP, GLUE SST-2, MultiNLI, Rotten Tomatoes
Multilingual (8): Wikipedia in Arabic, Chinese, French, German, Japanese, Korean, Portuguese, Spanish
Roleplay and Character (4): Airoboros 3.2, Glaive Function Calling V2, Cinematika, Limarp Lustoria
---
## TRAINING DATA MIX SYSTEM
- Per-dataset percentage sliders for exact data composition control
- 4 pre-balanced presets with conversation-heavy mixes:
- 200M: 20 datasets (35% web, 35% conversation, 30% specialized)
- 500M: 30 datasets (28% web, 40% conversation, 32% specialized)
- 750M: 40 datasets (24% web, 36% conversation, 40% specialized)
- 1B: 50 datasets (20% web, 35% conversation, 45% specialized)
- 13% reserved for your custom examples (5% conversations.txt + 8% thinking.txt)
- Auto Balance button, tiny allocations auto-skipped, mix saved between sessions
---
## SMART FORMAT AUTO-DETECTION
Automatically detects and converts 10+ dataset formats into training-ready text:
- Plain text, instruction/output, instruction+input+output, conversation JSON, chain-of-thought with rationale, XML think/answer tags
- Text cleaning: strips HTML/URLs, removes non-ASCII, collapses whitespace, preserves User/Bot structure
---
## OUT-OF-CORE DATA STREAMING
Train on datasets larger than your RAM:
- Row-group-at-a-time parquet reading - never loads full files into memory
- Configurable chunk rotation (default 10M chars every 1,000 steps)
- Fisher-Yates shuffle buffer for data variety
- Per-dataset progress tracking with resume across chunks
- Datasets stored in ~/TinyBrainData/ - survives reinstalls
---
## CHAT INTERFACE
- Custom-drawn chat bubbles (green for user, dark for bot) with rounded corners
- Timestamps and confidence scores on every message
- Context state indicators: green border (active), yellow (summarized), red (forgotten)
- Automatic conversation summarization when history exceeds 80% of context window
- Chat persistence: auto-saves/loads between sessions, stores full history + persona
---
## THINKING MODE (CHAIN-OF-THOUGHT REASONING)
Toggle thinking to enable reasoning mode - like o1 and DeepSeek-R2:
User: What is the capital of France?
Think: France is a country in Western Europe. Its capital city is Paris.
Bot: The capital of France is Paris.
- Thinking bubble in chat (collapsible, italic, gray)
- Trained on User/Think/Bot format from thinking.txt and CoT datasets
- Two-pass generation: thought first, then response informed by thinking
- Auto-cleanup of leaked prefixes, no bubble if no useful thought
---
## PERSONA / SYSTEM PROMPT
- Collapsible left panel for system-level personality instructions
- Default: "You are TinyBrain, a helpful AI assistant."
- Injected as prefix during every generation, auto-saved to persona.txt
- Change personality mid-conversation without retraining
---
## GENERATION ENGINE
- Top-K sampling: configurable from 5 (focused) to 100 (diverse)
- Temperature scaling: 0.3 = precise, 0.6 = balanced, 1.0 = creative
- Repetition penalty: configurable penalty factor and window size
- Confidence tracking: average softmax probability displayed as 0-100% per response
- Response cleanup: cuts at newline, removes prefix leaks, trims to complete sentence
---
## GGUF MODEL EXPORT
Export your trained model to GGUF - load it in Jan.ai, Ollama, LM Studio, or any llama.cpp-compatible app:
- One-click export from the chat header
- GGUF v3 format with GPT-2 architecture metadata
- FP16 weight quantization (half file size vs FP32)
- Full GPT-2 byte-to-Unicode tokenizer encoding
- BPE vocabulary and merge rules in llama.cpp-compatible format
- Jinja2 chat template baked in (User/Think/Bot format)
- Persona/system prompt embedded in metadata
- Chain-of-thought thinking support in exported models
- All 29 model tensors: embeddings, attention, FFN, layer norms, LM head
---
## THUMBS UP / THUMBS DOWN FEEDBACK
- Thumbs up/down buttons on every bot message
- Category selection popup: Helpful, Accurate, Creative, Clear, Off-topic, Repetitive, Wrong, Incoherent, Too short, Too long
- All feedback saved permanently to JSONL (timestamp, prompt, response, rating, categories)
- Thumbs down auto-regenerates: removes bad response, injects feedback hint, regenerates with thinking if enabled
- Never affects model weights or context budget
---
## UI DESIGN
- Professional dark theme with green accent
- Resizable window with collapsible persona (left) and intelligence tracker (right) panels
- Segoe UI typography throughout, Segoe UI Emoji for feedback buttons
- Color-coded status bar: green=ready, orange=training, cyan=paused, red=error
---
## ERROR HANDLING
- Crash logging with full stack traces
- CUDA detection with clear error messages
- Tokenizer vocab validation (auto-retrains on mismatch)
- Checkpoint fingerprinting prevents loading wrong model
- NaN/Infinity loss detection
- Corrupt checkpoint recovery
- Hot-reload config changes without restart
---
## TECHNICAL SPECIFICATIONS
- Language: C# / .NET 8.0
- UI: Windows Forms
- ML Backend: TorchSharp (C# bindings to LibTorch)
- GPU: CUDA 11.8+ (NVIDIA)
- Data: Apache Parquet (HuggingFace native)
- Platform: Windows 10/11 (x64)
- Min VRAM: 3 GB (60M) to 34 GB (1B)
---
## WHAT MAKES THIS UNIQUE
1. Trains real GPT transformers from scratch on consumer hardware
2. Full visual interface - no command line, no Python, no notebooks
3. 144 curated datasets built in with one-click download
4. Pause training to chat with your partially-trained model
5. Intelligence probes show your model getting smarter in real-time
6. Full pipeline: tokenizer, data streaming, training, inference, chat, GGUF export
7. 100% local - zero cloud dependencies
8. Chain-of-thought reasoning (thinking mode) like frontier models
9. Auto-detects and converts 10+ dataset formats
10. Streams terabytes through out-of-core pipeline with minimal RAM
11. Exports to GGUF for Jan.ai, Ollama, LM Studio, llama.cpp
12. Built-in feedback system with thumbs up/down and auto-regeneration
Download
Leave a comment
Log in with itch.io to leave a comment.